ROI of probabilistic forecasting: An experimental case study
The critical role of uncertainty in forecasting is receiving a lot of attention. Advanced software vendors are now offering state-of-the-art probabilistic forecasts. Advanced companies are now incorporating these forecasts into their decision-making processes. But what’s the expected ROI? Will probabilistic forecasting become the new normal? In this article, we empirically demonstrate the added value of this approach in a real retail context.

Throughout this series of articles, I propose the analysis of various forecasting approaches from the point of view of their economic added value. 📈➡💰
To do so, I rely on a cost-oriented digital twin that simulates decisions and evaluates the associated costs for any forecast data.
This tool has been applied so far to analyse the added value of deterministic forecasting.
One of the very first uses of this digital twin was to analyze the relationship between forecast accuracy metrics and the actual business value-added from them. The results were stunning (and a bit counterintuitive for some readers). Indeed, this initial analysis demonstrated the low correlation (only 25%!) that exists between forecast accuracy metrics and business value. If you missed this key article, I highly recommend reading it 👉[2]…
In the following articles, even more has been demonstrated using this digital twin. For example, in one of the last articles, I listed no less than seven exclusive use cases that this new tool unlocks. This article has received hundreds of positive comments (and thankfully very few negative ones 😅). Again, if you missed it, it’s worth reading 👉[3]!
In this new article, I will use the same cost-oriented digital twin to shed light on a very important topic: probabilistic forecasting.
Over the past few years, this topic has been getting more and more attention. Today, in most publications, probabilistic forecasting is considered the new “must-have” in Supply Chain[4]. It is foreseen as the method that will replace the good old forecasting methods used for decades.
And indeed, from a theoretical point of view, the probabilistic approach seems definitely much more appropriate for our needs than the deterministic one. But discussing theory is beyond the scope of this article. If you want to know more about it, I strongly recommend you to check out Stefan de Kok’s comprehensive list of publications on probabilistic forecasting 👉[5].
Rather than discussing the theory, I’ll here focus exclusively on measuring the actual value-added of this new approach. Since few studies address the actual value-added of probabilistic forecasting, I hope this one will help companies make informed choices about whether to adopt probabilistic forecasting.
From deterministic to probabilistic forecasting: 101
🤭I know… I just promised I wouldn’t discuss theory here… and the purpose of this chapter is to describe the concepts behind the different forecasting approaches… Yet, I think this chapter is mandatory for those who are not familiar with the three methods discussed in this article.
But if you are not interested, feel free to skip this chapter and go directly to the next section!
Still there? Great! So let’s share some basics about deterministic, quantile and probabilistic forecasting.
Deterministic forecasting
Deterministic (or point) forecasting is the category of forecasting that has been used for decades in the supply chain. There is a 99% chance that this is the category of techniques that your company is currently applying.
The purpose of these forecasting methods is to predict “what the future will be,” as exactly as possible. Of course, the future is (and always will be) uncertain. Therefore, these predictions are always wrong. This is why forecasts are so often criticized for being wrong.
In fact, the predicted points are usually midpoints. There is a 50% chance that the future will be better, a 50% chance that the future will be worse. Flip a coin!

Yet, in the decision-making process that consumes these forecasts, these points are almost always considered “the truth.” Every decision is based on the assumption that these forecasts will occur as predicted.
Of course, practitioners are well aware that the future is unknown. So, to prepare for the unexpected, they often add some cushion.
This is typically the case with safety stocks. Safety stocks are set to protect against higher than expected demand. They are usually defined on the assumption that demand follows a normal distribution. The implementation of safety stocks allows increasing the service level from 50% (forecast only) to for example 90/95/99% (forecast + safety stock).
Quantile forecasting
The core idea of the quantile approach is to forecast a specific percentile (90/95/99%) instead of the usual median percentile (50%). It is therefore a deliberately biased forecast 😲!
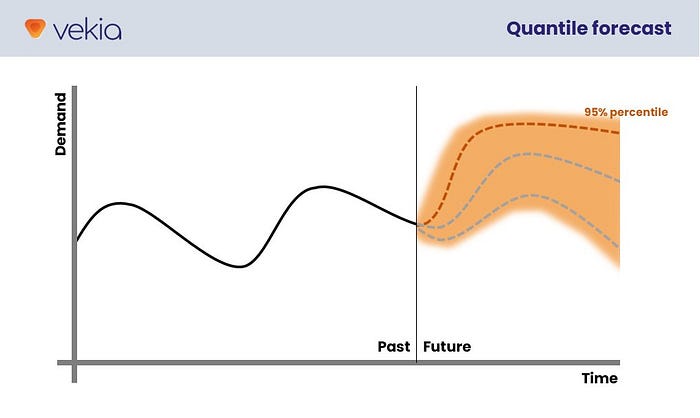
The important point here is that the uncertainty is now part of the forecast itself. There is no longer a need to set a separate safety stock (at least to protect against the variability of the demand). The cycle stock and the safety stock are now merged into a stock level that dynamically evolves based on the forecast.
As such, quantile forecasting allows for more accurate decision making and, when done properly, gets rid of the erroneous assumption that demand follows a normal distribution.
On the one hand, the positive point here is that a quantile forecast can easily be consumed by an existing decision process with a simple tweak (essentially plugging in the quantile forecast and unplugging the safety stock calculation).
But on the other hand, the forecasts generated still describe a single percentile. As such, they do not describe the full uncertainty that must be faced.
Probabilistic forecasting
Instead of providing a point forecast (whether it is the 50% or the 90/95/99% percentiles), the core idea is to describe the entire probability distribution.
The objective of this forecasting approach is therefore to describe “what the future might be” rather than to predict “what the future will be”.
“It is better to be vaguely right than exactly wrong” — Carveth Read (1920)
For example, such a distribution might look like this:
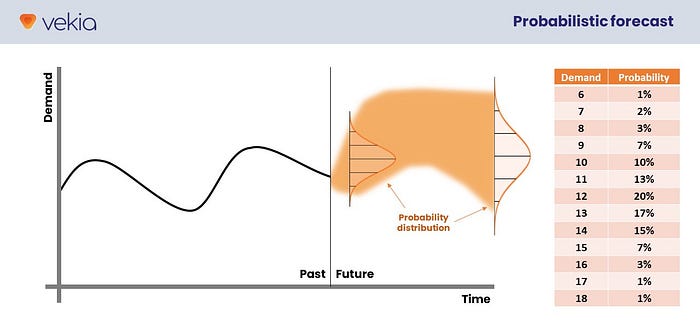
These probabilities sum up to 100%.
Another approach is to describe n-levels of percentiles.
Since the entire uncertainty is now described, probabilistic forecasting provides much more information than any other forecasting approach.
Of course, since the output of forecasting is totally different from what we are used to (a distribution vs a single point), the way decisions are made must adapt. We now manipulate different concepts: probabilistic concepts.
Yet, the shift to probabilistic forecasting allows us to make even more informed decisions. We are finally able to consider all possible scenarios when making decisions.
Setting up the test bench
Dataset
For our study, we need data and probabilistic forecasts. How lucky we are 🤗! The M5 competition [6] organized in 2020 had two distinct tracks. The first was on “point forecasting” while the second was devoted to “probabilistic forecasting”.
In the second track, thousands of competitors from all over the world and from various backgrounds (academics, practitioners, data scientists, students, etc.) tried to estimate, as accurately as possible, the distribution of demand uncertainty at Walmart.
In both tracks, the M5 team shared some benchmark forecasts as well as the top 50 forecasts obtained. These constitute a fantastic playing field for this study (30,490 timeseries, 54 different forecast methods).
Replenishment strategy and cost structure assumptions
Here we will apply the same assumptions (regarding the replenishment strategy and cost structure) as described in the “What is not in this dataset” section of our original paper [1].
Basically, we will simulate a weekly replenishment with a 3-day lead time and a 95% target service level. We will include concepts such as packaging, holding costs, shortage costs, margin, etc.
Decision-making process
For the 3 different types of forecasts, we will apply a cost-oriented replenishment process, i.e. a process that evaluates different replenishment options and selects the one with the lowest costs.
- For the process using deterministic forecasts, we will consider the median forecast and safety stock at 95% of the service level.
- For the process using quantile forecasts, we will consider the 95% percentile and no safety stock.
- For the process using probabilistic forecasts, we will consider a minimum service level constraint of 95% and no safety stock.
For the cost estimation, we compute the expected mathematical value for the costs of each demand probability.
Analyzing the results
First analysis: checking the basics
How do “50% percentile” forecasts and “deterministic” forecasts compare?
Here is the idea: there should be no massive difference between a deterministic forecast and a probabilistic forecast where only the median (50% percentile) is considered. Both forecasting approaches should provide approximatively the same forecast, trigger the same decision and incur the same costs, right?
The purpose of this first test is therefore to compare the costs of the two different types of forecasts.
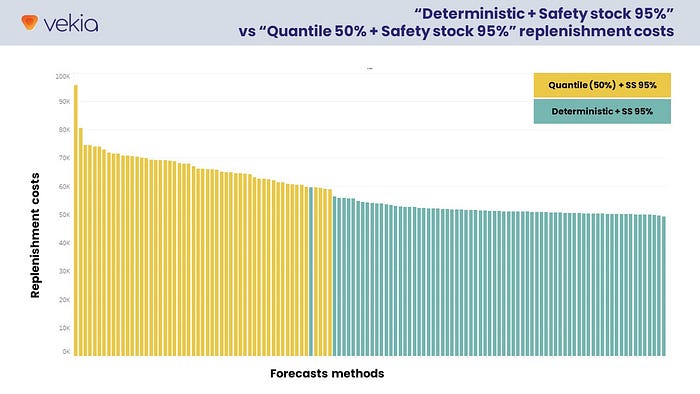
Despite the theory, the results here are different. 🤯
- Deterministic forecasts trigger a very compact set of replenishment decision costs ranging from $49k to $59k (median $51k).
- Quantile forecasts (50% percentile) trigger a wide range of replenishment costs from $59k to $95k (median $66k), thus performing much worse than deterministic forecasts.
How could that be?
Well… there are multiple possible reasons for such a difference.
The most interesting assumption is that when generating a probabilistic forecast, demand planners try to be qualitative about each quantile. Put another way, to improve the overall performance metric, it is acceptable to decrease the quality of a single quantile (including the median).
Conversely, deterministic forecasting focuses exclusively on the quality of this median percentile, thus generating better results.
What can we conclude from this?
Probabilistic forecasts are not designed to be analyzed in a deterministic way. It is like evaluating the performance of a Formula 1 car in a WRC championship.
This first analysis is therefore interesting, but it says little about the effective added value of probabilistic forecasting.
Second analysis: quantile forecasting vs deterministic forecasting
Is there any added value in switching from deterministic to quantile forecasting?
As mentioned before, the core idea of quantile forecasting is to deliberately provide biased forecasts.
By doing so, it is possible to replace the traditional safety stocks (calculated based on the normal distribution of demand) with a forecast directly targeting the required service level.
For example, it is theoretically possible to replace a deterministic forecast associated with a 95% service level safety stock with a quantile forecast (95% percentile).
Let’s see if such a change adds value or not?
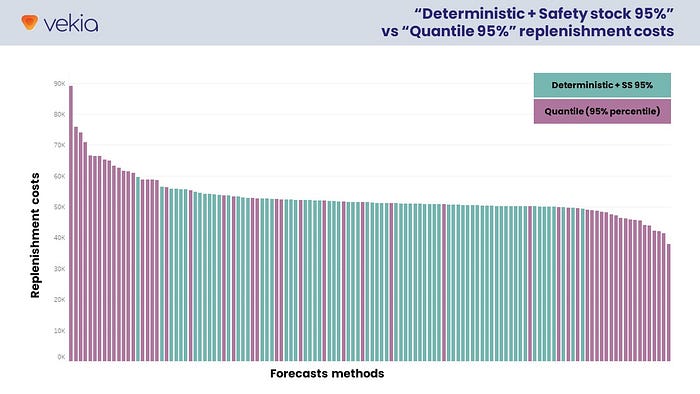
Here, the theory is experimentally validated. 🤩
- (Same as before) Deterministic forecasts trigger a very compact set of replenishment decision costs ranging from $49k to $59k (median $51k).
- Quantile forecasts (95% percentile) trigger a wide range of replenishment costs from $38k to $89k (median $52k).
Thus, on average, the deterministic forecasts still perform better (2%) than the quantile forecasts. But, it is interesting to note that :
- 40 quantile methods (74%) now perform as well as deterministic methods.
- 18 quantile methods (33%) outperform all other deterministic methods.
- The best quantile method allows a 23% decrease in replenishment costs (-$11.5k) compared to the best deterministic method.
What can we conclude from this?
The transition from a deterministic approach to a quantile approach does not systematically generate added value. Worse, if it is not done properly (26% of methods), it might decrease the overall business performance.
Nevertheless, when an appropriate forecasting method is chosen, the switch from a deterministic to a quantile approach can lead to really important improvements.
Third analysis: probabilistic forecasting vs deterministic forecasting
What about probabilistic forecasting? Is there added value in moving from deterministic to probabilistic forecasting?
As mentioned, the concept of probabilistic forecasting is to fully describe the distribution of uncertainty instead of giving a single number as an outcome (the median or a specific quantile).
In this way, it is theoretically possible to take into account all possible future scenarios when making decisions, and thus to propose smarter replenishments that take uncertainty into account and are optimized for it.
Let’s see if this theory is confirmed…
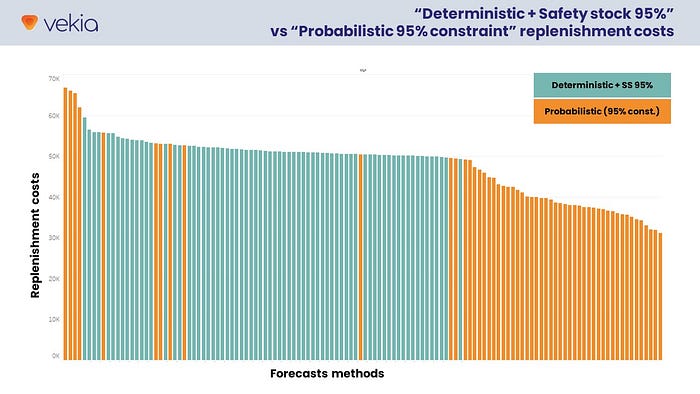
The theory is here again experimentally validated. 🤩
- (Same as before) Deterministic forecasts trigger a very compact set of replenishment decision costs ranging from $49k to $59k (median $51k).
- Probabilistic forecasts (95% min service-level constraint) trigger a wide range of replenishment costs from $31k to $67k (median $40k).
Thus, on average, the probabilistic forecast performs better (-22%) than the deterministic forecast. Moreover, it is interesting to note that :
- 50 probabilistic methods (93%) now perform as well as deterministic methods.
- 42 probabilistic methods (78%) outperform all other deterministic methods.
- The best probabilistic method allows a 37% decrease in replenishment costs (-$18.2k) compared to the best deterministic method.
What can we conclude from this?
Here, although one-fifth of the methods still underperform the deterministic methods, most probabilistic methods yield massive improvements.
In addition, the best probabilistic method can reduce replenishment costs by more than one-third compared to the best deterministic methods available to us.
Let’s sum it up!
To sum up, let’s represent all these costs in a single graph.
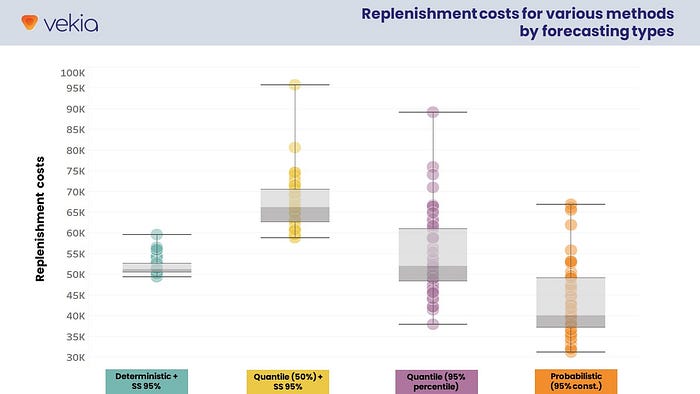
This representation of the distribution of the costs is very interesting…
However, the graph is polluted by poor quality methods that could lead us to wrong conclusions. Indeed, in the dataset, some poor-performing methods would have been quickly discarded in real life.
So, to make things clearer, let’s limit this graph to the 5 best methods of each type of forecast.

This highlights some important facts:
- 👉 Probabilistic forecasts transformed into deterministic forecasts (yellow) perform worse than pure deterministic forecasts (blue) when the 50% percentile is the only percentile considered.
- 👉 Switching from probabilistic forecasts transformed into deterministic forecasts (yellow) to quantile forecasts (purple) and then to probabilistic forecasts (orange) systematically improves significantly performance.
- 👉 The best deterministic methods (blue) all have more or less the same performance.
- 👉 The best quantile methods (purple) outperform purely deterministic methods (blue) by 11% to 23%.
- 👉 The best probabilistic methods (orange) outperform pure deterministic methods (blue) by 37% to 48%.
Conclusion
We started this article with two questions about probabilistic forecasting:
- What is the return on investment?
- Will probabilistic forecasting become the new normal?
At this point, we have demonstrated that probabilistic forecasting is much more than just marketing buzz. This new approach is not only better from a theoretical point of view but it is also capable of bringing massive benefits to companies, reducing costs by a third.
Decades of deterministic practices have helped companies improve their forecasting practices year over year. Recent technological advances (such as machine learning) have helped improve performance even more. But today, there is no more massive breakthrough to expect from machine learning.
I’m not saying that things won’t improve anymore. This field is still alive and performance will certainly continue to improve little by little. However, the “deterministic track” of the M5 competition has shown that we are reaching a glass ceiling in terms of performance: the best methods deliver more or less the same performance.
But by redefining the problem and focusing our attention on uncertainty, significant improvements are in sight. Forecasting and supply chain management is all about making informed decisions in an uncertain environment. Going back to those roots opens new perspectives and makes room for new solutions, such as probabilistic forecasting.
From this demonstration, and with a very low level of uncertainty, we can predict that deterministic forecasting will soon be replaced by probabilistic forecasting…
Deterministic forecasting is dead, long live probabilistic forecasting!
If you found this to be insightful, please share and comment… But also, feel free to challenge and criticize. And contact me if you want to discuss this further!
In all cases, stay tuned for the next articles! In the meantime, visit our website www.vekia.fr to know more about our expertise and experience in delivering high value to Supply Chain.
Linkedin: www.linkedin.com/in/johann-robette/
Web: www.vekia.fr
References
[1] Vekia, J. Robette, “The last will be first, and the first last”… Insights from the M5-competition, 2021
[2] Vekia, J. Robette, What’s the hidden cost of a forecast accuracy metric? — Insights from the M5-competition, 2021
[3] Vekia, J. Robette, Forecasting when accuracy is no longer the goal: a new world of possibilities, 2021
[4] Gartner, T. Payne, Maverick Research: ‘Demand-Driven’ Is Deadly to Your Supply Chain, 2021
[5] Wahupa, S. De Kok, Supply Chain Articles By Topic (Probabilistic Concepts section), 2015–2021
[6] M5 Competition website, The M Open Forecasting Center (MOFC)
